AI Integration
WebSockets en la API de OpenAI
Miguel Sánchez·28-02-2026
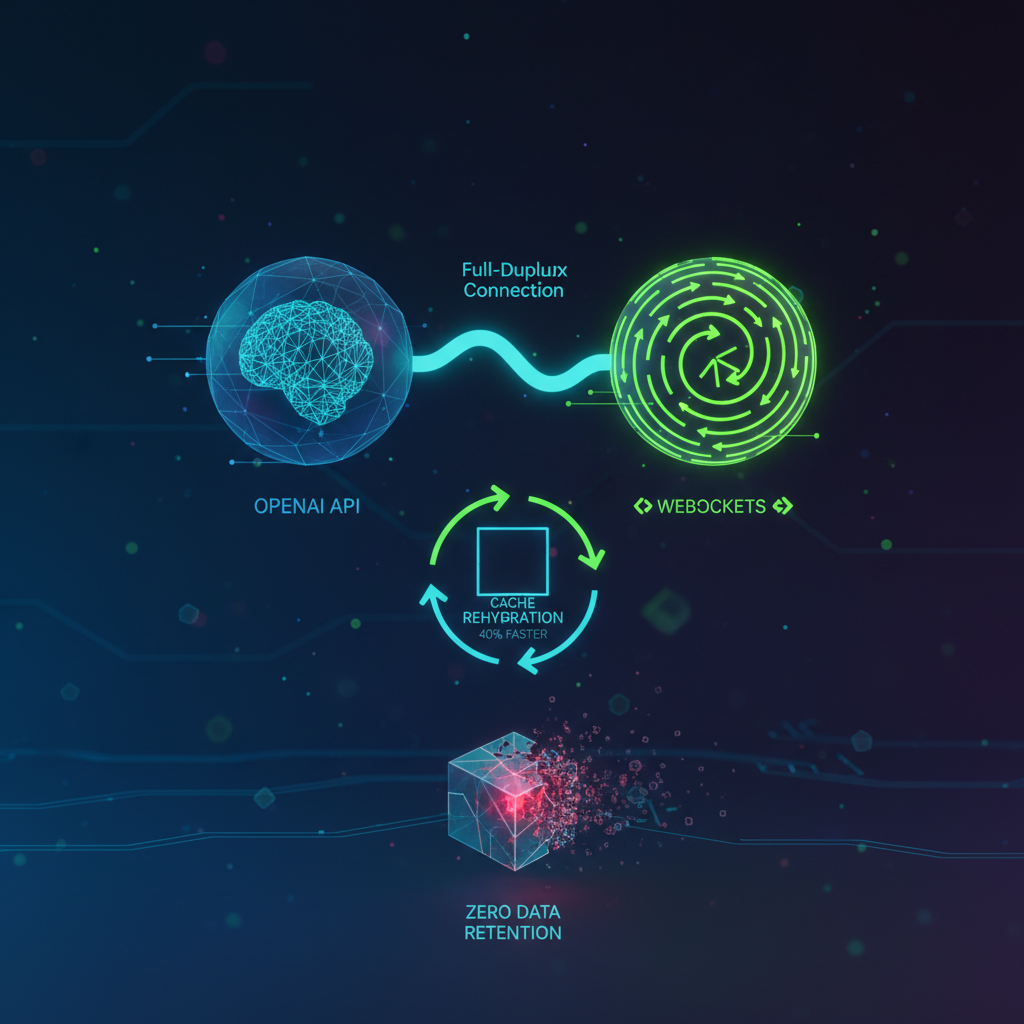
Beneficios Principales
- Baja latencia y mayor velocidad: Al mantener una conexión Full-Duplex persistente, se eliminan los tiempos de establecimiento de conexión. Para agentes que usan múltiples herramientas, la velocidad aumenta hasta un 40%. En aplicaciones de voz, la latencia se reduce a menos de 500 milisegundos.
- Eficiencia de memoria: El servidor retiene el estado de la sesión en su memoria local (RAM). Esto permite enviar solo las entradas nuevas vinculadas a un
previous_response_id, ahorrando tokens y poder computacional. - Interacciones de voz nativas: Elimina componentes intermedios de transcripción texto a voz. Incluye Detección de Actividad de Voz Semántica (VAD) para interpretar pausas sin interrupciones torpes.
- Sincronización en tiempo real: Las tareas largas o que requieren confirmación humana se actualizan inmediatamente en múltiples dispositivos sin infraestructura adicional.
Cambios Clave en la Arquitectura
Pasar a WebSocket implica un cambio radical en la forma de programar:
- Nuevos Endpoints: Las peticiones pasan de
https://awss://api.openai.com/v1/responses(para agentes de texto/herramientas) ewss://api.openai.com/v1/realtime(para asistentes de voz). - Estado Incremental ("Diffs"): Ya no se envía el arreglo completo de mensajes. El desarrollador solo envía las entradas nuevas referenciando el
previous_response_id. Enviar el historial completo anula las ventajas de velocidad. - Arquitectura impulsada por eventos: El modelo asíncrono requiere "listeners" para eventos JSON como
session.createdoresponse.audio.delta. - Gestión activa de la conexión: Existen límites estrictos, como el corte forzoso de la conexión a los 60 minutos.
- Procesamiento estrictamente secuencial: No se permite multiplexación; solo puede haber una respuesta a la vez por conexión. Para acciones paralelas, se requieren múltiples WebSockets.
Estrategias para la "Retención Cero de Datos"
Dado que la memoria caché en el modo WebSocket reside en la memoria RAM volátil del servidor, una desconexión elimina por completo el contexto. No existen respaldos ni logs de recuperación en OpenAI. El "cerebro del agente se vacía". Para manejar esto, la aplicación cliente debe asumir interrupciones:
- Almacenamiento local y rehidratación: El cliente debe llevar un registro local. Tras una desconexión, se debe abrir un nuevo socket y retransmitir el historial para "rehidratar" la memoria desde cero.
- Compactación manual: Si el historial es muy largo, se puede usar el endpoint independiente
responses compactmediante HTTP para obtener una versión resumida, abrir un novo WebSocket con este resumen e iniciar con unprevious_response_idnulo. - Retroceso (Fallback) a un estado válido: Si un error 400 o 500 interrumpe el servicio, OpenAI desaloja el ID de la memoria para evitar corrupción. El sistema debe retroceder al último estado funcional conocido y reintentar.
- Prevención del límite de 60 minutos: Se deben implementar monitores (heartbeats). Al minuto 55, el sistema debe pausar, compactar, cerrar el socket de forma segura y transferir el estado a una nueva conexión antes de que la API la corte.
¿Responses API o Realtime API?
- Responses API: Optimizada para flujos de texto, herramientas y agentes autónomos. Ideal para orquestadores y ejecución de código.
- Realtime API: Construida para baja latencia en interacciones de "voz a voz". Procesa audio crudo (como PCM16) nativamente mediante fragmentos minúsculos (chunks) junto al Semantic VAD.