AI Integration Miguel Sánchez·2/28/2026
Miguel Sánchez·2/28/2026
The WebSocket Revolution in the OpenAI API: Saying Goodbye to REST HTTP
Miguel Sánchez·2/28/2026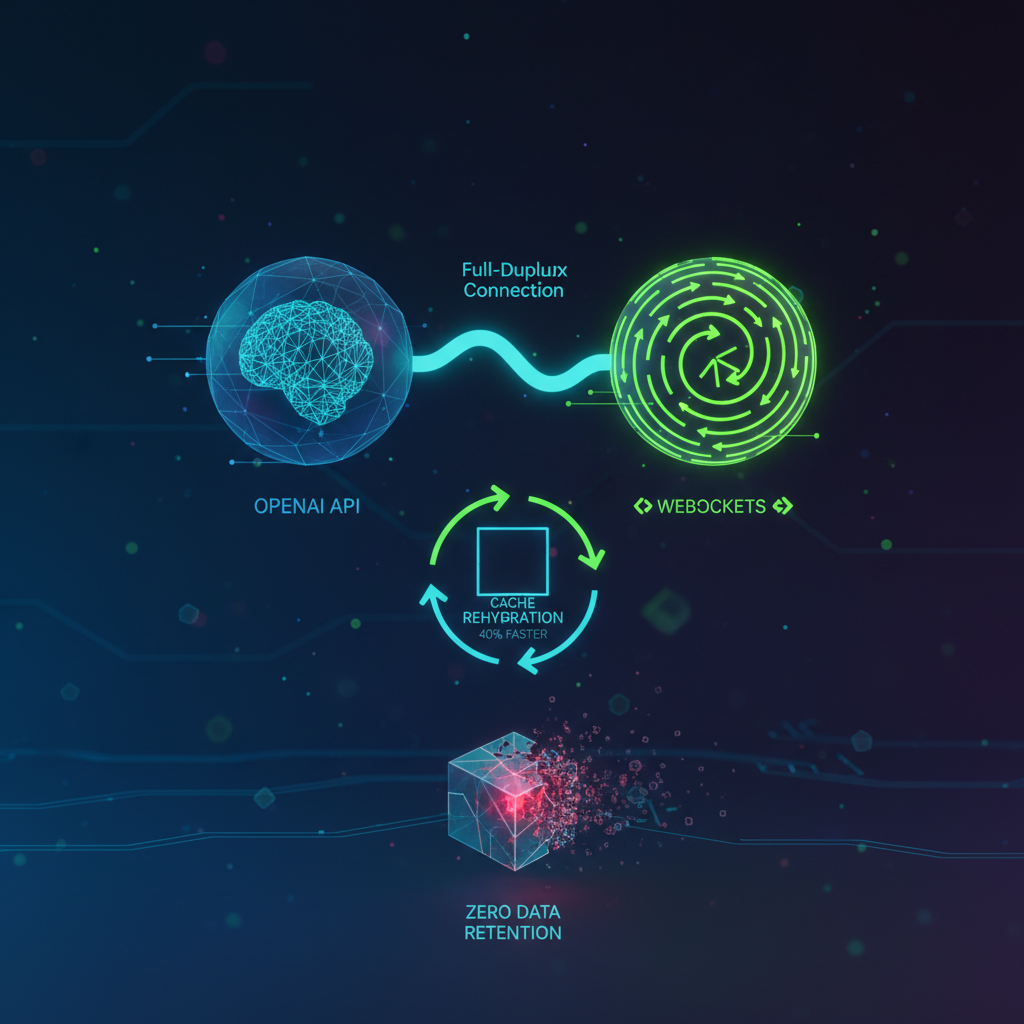
Core Benefits
- Low latency and higher speed: By maintaining a persistent Full-Duplex connection, connection setup times are eliminated. For agents using multiple tools, speed increases by up to 40%. In voice applications, latency drops below 500 milliseconds.
- Memory efficiency: The server retains the session state in its local memory (RAM). This allows developers to send only new inputs linked to a
previous_response_id, saving tokens and computational power. - Native voice interactions: Eliminates intermediate text-to-speech transcription components. It includes Semantic Voice Activity Detection (VAD) to interpret pauses without awkward interruptions.
- Real-time synchronization: Long-running tasks update immediately across multiple devices without additional infrastructure.
Key Architectural Changes
Moving to WebSockets implies a radical change in development:
- New Endpoints: Requests move from
https://towss://api.openai.com/v1/responses(for text/tool agents) andwss://api.openai.com/v1/realtime(for low-latency voice assistants). - Incremental State ("Diffs"): The entire message array is no longer sent. The developer only sends new inputs referencing the
previous_response_id. Sending the full history nullifies the speed advantages. - Event-driven architecture: The asynchronous model requires "listeners" for JSON events like
session.createdorresponse.audio.delta. - Active connection management: Strict limits exist, such as a forced connection cut at 60 minutes.
- Strictly sequential processing: Multiplexing is not allowed; only one response can occur at a time per connection. For parallel actions, multiple WebSockets are required.
Strategies for "Zero Data Retention"
Since the WebSocket mode cache resides in volatile server RAM, a disconnection completely wipes the context. There are no backups or recovery logs at OpenAI. The "agent's brain empties". To handle this, the client application must assume interruptions:
- Local storage and state rehydration: The client must keep a local record. Upon disconnection, a new socket must be opened and the history re-transmitted to "rehydrate" memory from scratch.
- Manual compaction: If the history is too long, the independent
responses compactHTTP endpoint can be used to obtain a summarized version, open a new WebSocket with this summary, and start with a nullprevious_response_id. - Fallback to a valid state: If a 400 or 500 error interrupts the service, OpenAI evicts the ID from memory to prevent corruption. The system must rollback to the last known working state and retry.
- 60-minute limit prevention: Heartbeats must be implemented. At minute 55, the system should pause, compact, safely close the socket, and transfer the state to a new connection before the API cuts it.
Responses API or Realtime API?
- Responses API: Optimized for text flows, tools, and autonomous agents. Ideal for orchestrators and code execution.
- Realtime API: Built for low latency in "voice-to-voice" interactions. Natively processes raw audio (like PCM16) via tiny chunks alongside Semantic VAD.