AI Integration Miguel Sánchez·28/02/2026
Miguel Sánchez·28/02/2026
A Revolução dos WebSockets na API da OpenAI: Adeus ao REST HTTP
Miguel Sánchez·28/02/2026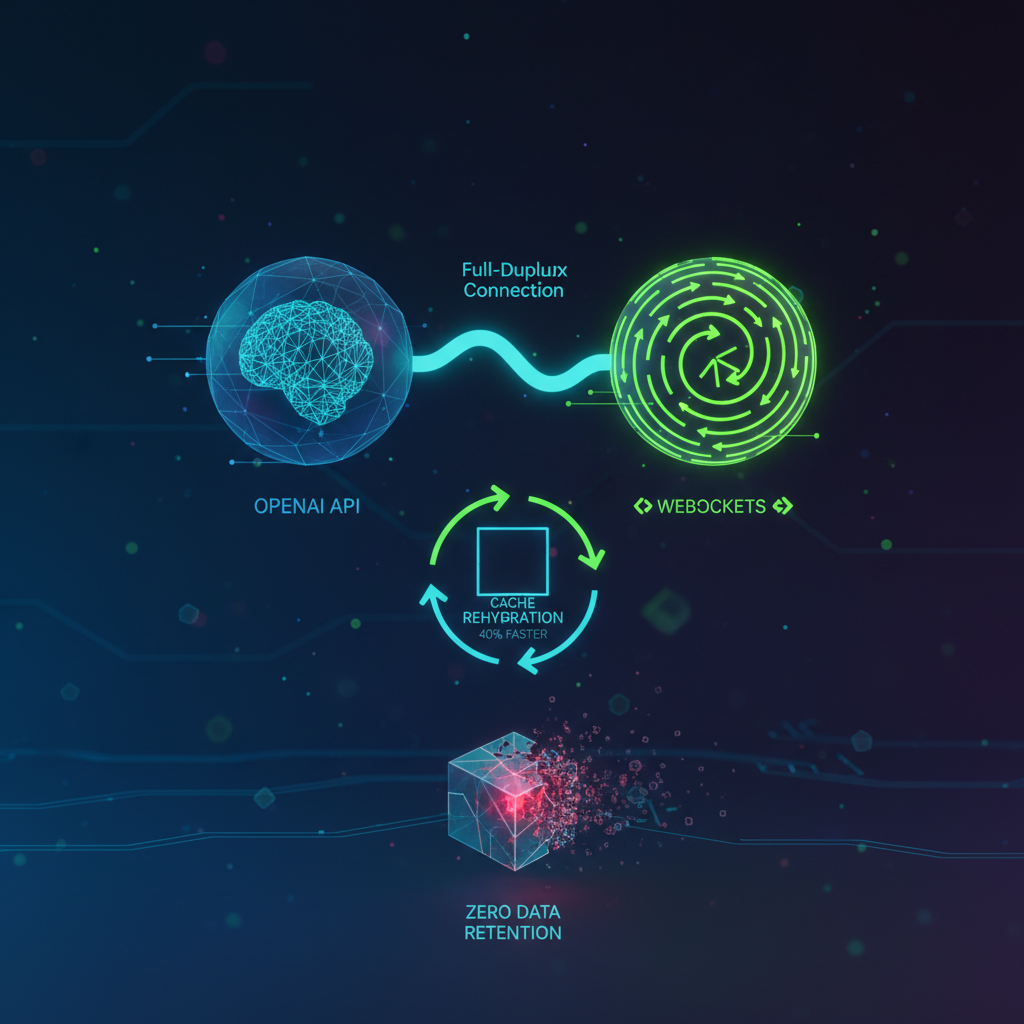
Principais Benefícios
- Baixa latência e maior velocidade: Ao manter uma conexão Full-Duplex persistente, os tempos de estabelecimento de conexão são eliminados. Para agentes que usam múltiplas ferramentas, a velocidade aumenta em até 40%. Em aplicações de voz, a latência cai para menos de 500 milissegundos.
- Eficiência de memória: O servidor retém o estado da sessão em sua memória local (RAM). Isso permite o envio apenas de novas entradas vinculadas a um
previous_response_id, economizando tokens e poder computacional. - Interações de voz nativas: Elimina componentes intermediários de transcrição de texto para voz. Inclui Detecção Semântica de Atividade de Voz (VAD) para interpretar pausas sem interrupções indesejadas.
- Sincronização em tempo real: Tarefas longas são atualizadas imediatamente em vários dispositivos sem infraestrutura adicional.
Mudanças Chave na Arquitetura
Mudar para WebSockets implica uma mudança radical na programação:
- Novos Endpoints: As solicitações mudam de
https://parawss://api.openai.com/v1/responses(para agentes de texto/ferramentas) ewss://api.openai.com/v1/realtime(para assistentes de voz). - Estado Incremental ("Diffs"): O array completo de mensagens não é mais enviado. O desenvolvedor apenas envia as novas entradas referenciando o
previous_response_id. Enviar o histórico completo anula as vantagens de velocidade. - Arquitetura orientada a eventos: O modelo assíncrono requer "listeners" para eventos JSON como
session.createdouresponse.audio.delta. - Gestão ativa da conexão: Limites rígidos existem, como o corte forçado da conexão aos 60 minutos.
- Processamento estritamente sequencial: A multiplexação não é permitida; apenas uma resposta pode ocorrer por vez por conexão. Para ações paralelas, múltiplos WebSockets são necessários.
Estratégias para "Retenção Zero de Dados"
Dado que o cache no modo WebSocket reside na memória RAM volátil do servidor, uma desconexão apaga completamente o contexto. Não há backups ou logs de recuperação na OpenAI. O "cérebro do agente esvazia". Para lidar com isso, o aplicativo cliente deve presumir interrupções:
- Armazenamento local e reidratação de estado: O cliente deve manter um registro local. Após uma desconexão, um novo socket deve ser aberto e o histórico retransmitido para "reidratar" a memória do zero.
- Compactação manual: Se o histórico for muito longo, o endpoint HTTP independente
responses compactpode ser usado para obter uma versão resumida, abrir um novo WebSocket com esse resumo e iniciar com umprevious_response_idnulo. - Retorno (Fallback) a um estado válido: Se um erro 400 ou 500 interromper o serviço, a OpenAI remove o ID da memória para evitar corrupção. O sistema deve retornar ao último estado funcional conhecido e tentar novamente.
- Prevenção do limite de 60 minutos: Monitores de tempo (heartbeats) devem ser implementados. No minuto 55, o sistema deve pausar, compactar, fechar o socket com segurança e transferir o estado para uma nova conexão antes que a API a corte.
Responses API ou Realtime API?
- Responses API: Otimizada para fluxos de texto, ferramentas e agentes autônomos. Ideal para orquestradores e execução de código.
- Realtime API: Construída para baixa latência em interações "voz para voz". Processa áudio bruto (como PCM16) nativamente através de pedaços minúsculos (chunks) em conjunto com o Semantic VAD.